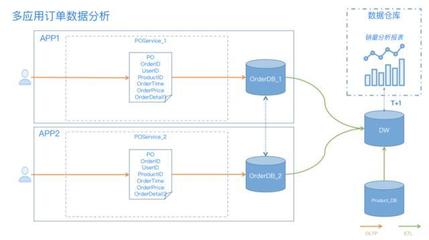
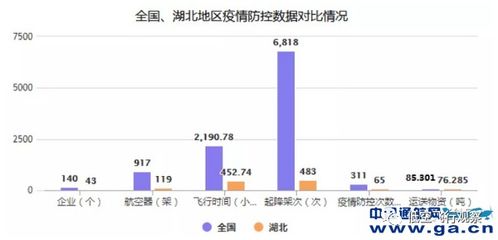
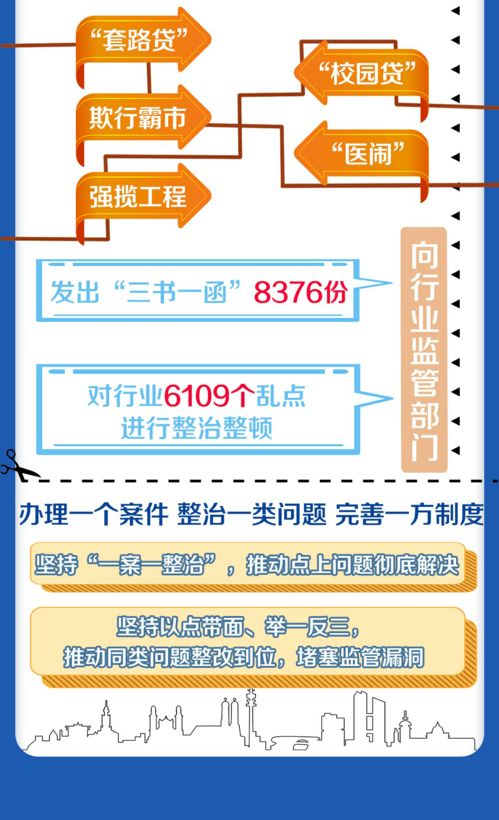
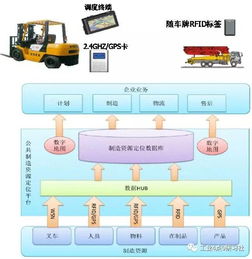
核心业务“瘦身”进行时 手把手教你构建海量数据实时处理架构
在当今数据驱动的商业环境中,企业的核心业务正面临着一场深刻的变革——“瘦身”与“增效”。传统的、笨重的数据处理方式已难以应对海量、高并发的在线业务需求,尤其是在线数据处理与交易处理业务。为了实现更敏捷的响应、更低的延迟和更高的可靠性,构建一套专为海量数据设计的实时处理架构已成为企业的必然选择。本文将手把手带你了解这一架构的核心要素与搭建思路。
一、 为何“瘦身”?传统架构的挑战
传统的核心业务系统往往采用单体架构或紧耦合的模块化设计,数据处理链路长、组件繁复。面对每秒数万乃至数百万级的交易请求和随之产生的海量数据流,传统架构暴露出诸多问题:
- 扩展性差:垂直扩容(Scale-up)成本高昂且存在上限,难以应对突发流量。
- 实时性弱:数据处理通常依赖批量作业(T2或隔日),无法满足实时风控、实时推荐、实时仪表盘等业务场景。
- 可靠性风险:单点故障可能导致整个业务链中断,影响交易连续性与数据一致性。
- 运维复杂:系统臃肿,故障定位难,变更和发布周期长。
因此,为核心业务“瘦身”,即解耦复杂流程、聚焦核心计算、实现弹性伸缩,是构建现代化实时处理架构的首要目标。
二、 实时处理架构的核心设计理念
一个健壮的海量数据实时处理架构应遵循以下设计理念:
- 流式优先:将数据视为持续不断的流(Stream),而非静止的池(Pool),实现毫秒级到秒级的处理延迟。
- 事件驱动:以业务事件(如:用户下单、支付成功)作为系统的通信核心,实现松耦合、高内聚的微服务或函数化组件。
- 弹性可扩展:采用云原生或分布式技术,支持水平扩容(Scale-out),根据负载自动调整计算资源。
- 端到端一致性:在分布式环境下,通过事务性消息、CDC(变更数据捕获)或Saga模式等技术,保障数据处理最终一致性或强一致性。
- 可观测性:内置完善的监控、日志、追踪体系,确保系统状态透明,便于快速排障与性能优化。
三、 手把手搭建:核心组件与数据流
一个典型的实时处理架构可抽象为以下四层,我们以电商交易场景为例进行串联:
1. 数据源与采集层
来源:前端APP/Web日志、业务数据库(如订单库、用户库)、IoT设备、合作伙伴API等。
工具:使用高吞吐量的消息队列作为“数据总线”,如Apache Kafka、Pulsar或RocketMQ。它们负责承接海量数据流,并解耦生产者和消费者。业务系统将交易事件(如“OrderCreated”)发布到指定Topic。
2. 实时计算与处理层(核心“瘦身”区)
角色:这是架构的大脑,负责从“数据总线”中消费消息,执行核心业务逻辑,但每个处理单元职责单一、轻量化。
技术选型:
* 流处理框架:Apache Flink(主流选择,提供精确一次语义、状态管理、复杂事件处理)、Spark Streaming等。
- 轻量级计算:对于简单过滤、转换,也可使用配合消息队列的轻量级消费者服务(如Go/Java微服务)。
- 处理示例:
- 实时风控:Flink作业消费订单流,实时查询用户画像(旁路缓存如Redis),应用规则模型,判断交易风险并输出风险事件。
- 实时统计:Flink作业实时计算每秒成交额(GMV)、热门商品,结果写入下游数据库供Dashboard展示。
- 数据丰富与转换:将订单流水与商品信息、用户信息进行实时关联,形成宽表数据流供下游消费。
3. 存储与查询层
角色:存储处理后的结果,并支持低延迟查询。遵循“右工具做右事”原则。
技术选型:
* 实时OLAP:Apache Druid、ClickHouse,用于存储和快速聚合查询实时分析指标。
- 键值/缓存存储:Redis、Aerospike,用于存储实时用户会话、计数器、去重集合等。
- 分布式数据库:Cassandra、HBase,用于存储海量明细数据。
- 关系型数据库:MySQL(分库分表)、PostgreSQL,用于存储需要强一致性的核心业务数据(最终落地)。
4. 数据输出与服务层
角色:将处理结果服务于业务。
形式:
* 推模式:将实时预警消息通过WebSocket、推送服务通知给运营人员或客户。
- 拉模式:提供低延迟API,供前端应用查询实时仪表盘数据。
- 写回:将处理后的数据写回业务数据库或数据湖(如Iceberg、Hudi),供离线分析补充。
四、 关键实践与“瘦身”要诀
- 渐进式解耦:不要试图一次性重写整个系统。优先从最重要的、实时收益最高的业务场景(如交易风控、实时大屏)开始,将这部分逻辑从单体中剥离成独立的流处理作业。
- 状态管理:实时处理常需状态(如窗口计数、用户会话)。利用Flink等框架的托管状态功能,并设计好状态的TTL和清理策略,避免无限膨胀。
- 容错与一致性:确保消息队列(Kafka)和计算框架(Flink)配合,实现端到端的“精确一次”(Exactly-Once)处理语义,保证资金、库存等关键数据不重不漏。
- 资源与成本优化:实时计算资源是弹性的,利用K8s等容器平台实现自动扩缩容,在流量低谷时节省成本。
- 数据血缘与治理:架构复杂化后,必须建立实时数据血缘追踪,明确数据来源、处理过程和去向,这是系统可维护性的基石。
五、
为核心业务“瘦身”,构建海量数据实时处理架构,绝非简单的技术堆砌,而是一场以数据流为核心的业务架构重塑。它通过将笨重的批量处理拆分为轻盈、专注的实时流,使得在线数据处理与交易处理业务能够像神经系统一样,敏锐地感知并即时响应每一个业务事件。从消息队列的可靠接入,到流处理引擎的核心计算,再到多样化存储与即时服务,每一步都需要精心设计。
踏上这条“瘦身”之路,企业将收获的不仅是技术的升级,更是业务响应速度、用户体验和决策智能的质的飞跃,从而在数据洪流中赢得先机。
最新产品